
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

The 7 Best Python ETL Tools in 2026
The global big data analytics market is projected to reach a $655.53 billion valuation by 2029, compared to $241 billion in 2021. This massive growth shows how enterprises are increasingly turning to data analytics to guide various business operations.
As part of this shift, enterprises rely heavily on Extract, Transform, Load (ETL) processes for turning raw data into actionable insights. These processes are a key component in data warehousing and facilitate data movement between different organizational systems, increasing data accessibility. Various ETL tools are available today, written in different languages such as Java, Apache Hadoop, and JavaScript. However, ETL with Python — a general-purpose and high-level programming language — is among the leading choices.
This blog discusses what makes Python a great option for building an ETL pipeline, how you can set it up, and the best Python ETL tools and a better, no-code data integration alternative.
- Python ETL is flexible but complex: Python offers powerful libraries and frameworks for ETL, but building pipelines in code adds maintenance, debugging, and scalability overhead.
- Top orchestration tools: Tools like Apache Airflow and Luigi help you build, schedule, and monitor ETL workflows using Python.
- Data transformation libraries: Pandas (and other Python libraries) make transformations intuitive, but often lack built-in extraction or loading capabilities.
- Performance trade-offs: Native Python ETL can hit performance bottlenecks with large datasets due to memory limits and the GIL.
- Compatibility pain points: Versioning and dependency management across Python libraries and implementations (CPython, PyPy) can complicate long-term pipeline stability.
- No‑code alternative is compelling: Astera provides a chat-based ETL platform that avoids code while supporting ETL, ELT, transformation, and orchestration.
- Broad connectivity: Astera supports 100+ connectors for common data sources and destinations, letting you build flexible pipelines without custom Python code.
- Automation & monitoring: With Astera, you can schedule, monitor, and alert on pipeline executions — reducing manual effort compared to purely code-driven pipelines.
Python ETL Tools: An Overview
The phrase ‘Python ETL tools’ doesn’t refer to a single, monolithic software program. Rather, it’s a catch-all term for numerous libraries and frameworks built using Python for targeting different stages of the ETL process.
These stages and their corresponding Python ETL tools are listed below:
Workflow Management Tools
In Python ETL, workflow management helps you schedule engineering and maintenance processes. Workflow applications such as Apache Airflow and Luigi, while not designed explicitly for ETL processes, can help you execute them through the following features:
- Dependency Management: By defining task dependencies, you can ensure that tasks are executed in the correct sequence. This is crucial for data integration processes where extraction must precede transformation, which in turn must precede loading.
- Scheduling: Scheduling ETL tasks lets you run them at defined intervals or specific times, which automates the process and ensures the availability of timely updates.
- Parallel Execution: Workflow management tools let you run multiple tasks concurrently so that you can process data faster.
- Monitoring and Logging: These tools’ monitoring dashboards and logging capabilities let you track ETL tasks’ progress and identify and fix any issues.
- Retry Mechanisms: These tools can automatically retry failed tasks in case of disruptions or failures to ensure data integrity.
- Alerting: You can set up alerts or notifications in case of task failure or other instances to proactively manage your ETL processes.
- Dynamic Workflows: You can configure dynamic workflows in these tools that adapt to changes in schemas, data sources, or business requirements — increasing your ETL processes’ flexibility and adaptability.
- Code Reusability: Thanks to modularization and code reuse, you can efficiently build ETL pipelines and maintain them over time.
- Integration with Python Libraries: These tools integrate seamlessly with Python libraries and packages that are designed for data processing and analytics tasks, such as pandas, NumPy, and SciPy.
- Extensibility: Workflow management tools’ extensibility lets you integrate with different data sources, external systems, and databases through custom operators and plugins.
Tools for Moving and Processing Data
Python tools that handle data movement and processing can also help you design Python ETL workflows. Here’s how:
- Data Extraction: BeautifulSoup, requests, and similar libraries help with web scraping and API access for obtaining data from disparate sources.
- Data Transformation: pandas and NumPy offer remarkable data manipulation capabilities, and NLTK and spaCy can help with text processing.
- Data Loading: Python has database connectors (such as SQLAlchemy) that help you load transformed data into databases.
- Automation and Workflow: You can automate ETL processes using Python scripts or use a workflow management tool (like Apache Airflow) as discussed above
- Error Handling and Logging: Python has try-except blocks to handle errors, and the logging module ensures visibility into ETL task execution.
- Parallel Processing: Multiprocessing and threading enable parallel task execution, improving performance for large datasets.
- External System Integration: Python libraries offer easy integration with cloud services (such as boto3 for AWS), ensuring hassle-free interaction with external systems in a distributed environment.
Self-Contained Python ETL Toolkits
Python ETL toolkits are comprehensive libraries or frameworks offering end-to-end ETL capabilities within a single package. These toolkits’ integrated functionalities help you develop and deploy Python ETL pipelines easily — here’s how:
- Unified Environment: These toolkits provide a cohesive environment where you can perform all stages of ETL within the same framework without having to integrate multiple libraries or tools.
- Simplified Development: You get high-level abstractions and intuitive APIs for common ETL tasks within these toolkits, so you don’t have to write code for them.
- Pre-Built Components: Self-contained Python ETL toolkits are typically equipped with pre-built modules or components for handling frequently used data formats, databases, and transformations. This saves you time and effort and eliminates the need to code from scratch.
- Data Connectivity: These toolkits have built-in connectors and adapters for different data sources and destinations — such as databases, cloud storage, APIs, and file formats — to ensure seamless data movement across systems.
- Transformation Features: There’s a wide range of transformation methods, operators, or functions within these toolkits for data manipulation, enrichment, cleansing, and aggregation. This simplifies complex data transformations.
- Scalability and Performance: Self-contained Python ETL toolkits are often designed to scale with increasing data volume and have optimization features to enhance performance, such as parallel processing, caching mechanisms, and distributed computing.
- Monitoring and Management: These toolkits may have built-in monitoring, logging, and management functionalities to effectively track ETL jobs’ progress, resolve errors, and manage inter-task dependencies.
- Flexible Deployment: These toolkits offer flexibility in deployment, offering support for standalone applications, containerized environments like Docker, or integration with workflow management systems such as Apache Airflow.

Why Use Python for Building ETL Pipelines?
Here are some of the reasons behind using Python for ETL pipeline design:
Open-Source Accessibility
Python has been developed on an open-source, community-based model. The Python Software Foundation is dedicated to propagating Python open-source technology.
As an open-source language, Python has few restrictions when it comes to platform and run environments. It works well with different platforms and runs on Windows and Linux with minimal modifications.
While there are other open-source programming languages such as Java and R, Python offers greater ease of use and a far more extensive ecosystem of libraries and frameworks.
Big Data Suitability
Python requires less coding than other programming languages, making it simpler to write and maintain ETL scripts.
It’s also equipped with well-tested libraries for increased functionality. These libraries cater to some of the most common big data tasks, simplifying computing and analytics with packages for numerical computing, statistical analysis, visualization, machine learning, and data analysis.
Other languages such as Java and Scala have frameworks like Apache Hadoop and Apache Flink to support big data processing. However, Python’s simplicity makes it more preferable for ETL pipeline development and iteration.
Data Processing Speed
Python is known for its high data processing speed. Its code features a simpler syntax and is easier to manage than other programming languages, resulting in faster execution of tasks. Optimizations and parallelization techniques further improve Python’s data processing performance.
Lower-level languages such as C and C++ are often considered faster than Python for computational tasks. However, these languages typically require more complicated and verbose code, which ultimately slows development and affects its efficiency.
Support for Unstructured Data
Python also features built-in support for processing unstructured and unconventional data. Since most modern enterprise data is unstructured, Python is an organization’s key asset in this domain. Compared to other programming languages, this is where Python’s readability wins out and makes it particularly suitable for unstructured data processing.
The language features resources that can effectively tackle unstructured data processing challenges. Here are a few examples:
- Natural Language Toolkit (NLTK): Has a suite of programs and libraries for natural language processing.
- spaCy: A Python library for enterprise-grade Natural Language Processing (NLP), with pre-trained models for various NLP tasks.
- scikit-learn: A Machine Learning (ML) library with multiple data analysis and preprocessing tools.
All of The Python ETL Functionality, None of The Code
With Astera Data Pipeline, you can rapidly build, deploy, and automate ETL pipelines that are tailored to your business requirements — no coding, just a few clicks. Get started today.
Start Your FREE Trial
How to Build an ETL Pipeline in Python
Below is an example of setting up an ETL pipeline using Python, specifically the Pandas library.
The use case here involves extracting data from a CSV file, transforming it to add a new column indicating the length of text in a specific column, and then loading the transformed data into a new CSV file.
Step 1: Extract Data

Here,
- The function ‘extract_data’ uses the path to the input CSV file (‘input_file’) as its parameter.
- Inside the function, the ‘pd.read_csv()’ from the pandas library reads the data from the CSV file into a pandas DataFrame.
- The DataFrame containing the extracted data is returned.
Step 2: Transform Data

Here,
- The function ‘transform_data’ takes the extracted DataFrame (‘data’) as its parameter.
- Inside the function, the new column ‘text_length’ is added to the DataFrame using ‘data[‘text_column’].apply(lambda x: len(str(x)))’. This lambda function will calculate the length of the text in each row of the ‘text_column’.
- The transformed DataFrame is returned.
Step 3: Load Data

Here,
- The function ‘load_data’ takes the transformed DataFrame (‘data_transformed’) and the output CSV file’s path (‘output_file’) as its parameters.
- Inside the function, ‘data_transformed.to_csv()’ writes the transformed data to a new CSV file specified by ‘output_file’. Lastly, ‘index=False’ helps avoid writing row indices to the CSV file.
Input and Output File Paths

Here, two paths are specified. One to the input CSV file containing the data to be processed (‘input_file’) and the other to the output CSV file where the transformed data will be saved (‘output_file’).
Executing The ETL Process
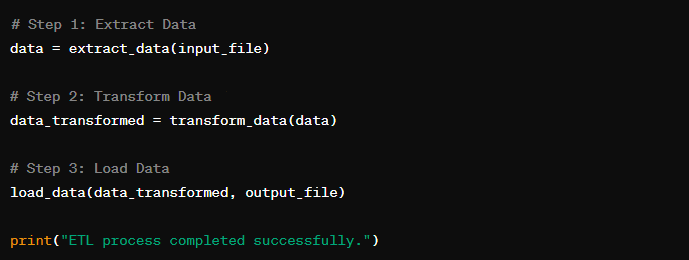
Here,
- The Python ETL process is executed by calling the ‘extract_data’, ‘transform_data’, and ‘load_data’ functions sequentially with the appropriate arguments.
- The extracted data is stored in the ‘data’ DataFrame.
- The ‘transform_data’ function is called with the extracted (‘data’) as input, and the transformed data is stored in the ‘data_transformed’ DataFrame.
- Lastly, the transformed data is loaded into the output CSV file specified by ‘output_file’.
Note that this code creates a very basic Python ETL pipeline. The more data an organization generates and consumes, the more complex the pipelines it will need to build and maintain. When it comes to building ETL pipelines in Python, increasing complexity can outweigh the benefits — which makes Python ETL tools a more feasible alternative.
The Best Python ETL Tools in 2026
Some of the best Python ETL tools are discussed below:
1. Apache Airflow
Apache Airflow is an open-source Python framework that uses Directed Acyclic Graphs (DAGs) to let users organize and manage their ETL pipelines. It supports the authoring, scheduling, and monitoring of workflows.
2. Luigi
Luigi was originally developed by Spotify and is a Python framework that enables users to stitch multiple tasks together.
3. Pandas
The Pandas library features the DataFrame object, a data structure that allows easy, user-friendly data manipulation. How Pandas simplifies data transformation is evident in the example of setting up ETL in Python, discussed earlier in this blog.
4. Petl
Petl is ideal for meeting basic ETL requirements without advanced analytics.
5. Bonobo
Bonobo is a simple, lightweight Python ETL framework that allows users to build data pipelines via scripting.
6. Pyspark
As a Python API, PySpark allows users to access and use Apache Spark (the Scala programming language) directly through Python.
7. Bubbles
What differentiates Bubbles from the other Python ETL tools discussed here is its metadata-based pipeline descriptions. This framework is written in Python but isn’t limited to it and features easy usability with other languages.
When Should You Use a Python ETL Tool?
Python ETL tools are ideal in one or more of the following scenarios:
- When an organization wants to code its own ETL tool and has developers or programmers who are proficient in Python.
- When organizational ETL requirements are straightforward and easily executable.
- When ETL requirements are highly specific and only Python can cater to them effectively.

Astera as a Better Alternative to Python ETL
Despite their considerable benefits, most Python ETL tools also share some drawbacks, such as:
- These tools require substantial knowledge and proficiency in Python for building and automating custom ETL pipelines.
- Many tools are more suitable for small- to medium-scale processes.
- Some tools’ scalability and speed can be limiting factors for rapidly growing organizations.
Enterprises want an intuitive interface, high processing speeds, reliability, and scalability from their ETL solutions. Additionally, automating ETL testing using Python requires skilled ETL testers with proficiency in both ETL testing methodologies and the Python programming language.
Therefore, many organizations look for an alternative to standard Python ETL tools that eliminates the need for hiring and retaining professionals and the associated costs.
Enter Astera.
Astera offers a tried-and-tested no-code environment, support for natural language instructions, a unified interface, and hassle-free integration with different data sources and destinations. Its sophisticated data cleansing and transformation capabilities allow users to quickly turn raw data into refined insights.
It’s the leading Python ETL alternative for enterprises wanting to build, deploy, and maintain ETL pipelines without writing a single line of code.
Ready to automate your ETL processes? Book a demo or start a FREE trial today.
What are some popular Python ETL tools?
Popular Python ETL tools include Apache Airflow, Luigi, Pandas, and Dask, which let you write and orchestrate pipelines in code. Astera Centerprise offers a no-code, drag-and-drop ETL platform that also supports natural language instructions to simplify pipeline creation, translating plain-language descriptions into executable dataflows. Learn more about Centerprise.
Why do engineers use Python for ETL, and when might they use a platform like Centerprise instead?
Python is favored for flexibility and custom logic, but scaling pipelines, maintaining code, and enabling non-developers can be challenging. Centerprise addresses these issues with visual design, parallel processing, and natural language instructions, allowing teams to build complex ETL pipelines without writing code. Learn more about Centerprise.
What are the limitations of Python-based ETL at scale?
Python ETL can encounter memory constraints, concurrency limits, and orchestration complexity. Centerprise mitigates these challenges with a cluster-based engine for parallel execution and automated workflows, while natural language instructions reduce manual coding, making pipeline creation faster and less error-prone. Learn more about Centerprise.
Do Python ETL tools support real-time or event-driven pipelines?
Some Python frameworks (like Apache Beam) support streaming, but implementing real-time pipelines often requires significant custom code. Centerprise provides workflow automation, real-time triggers, and natural language instructions, enabling users to define streaming or event-driven dataflows simply by describing them in plain language. Learn more about Centerprise.
When should you choose a no-code ETL platform instead of building with Python?
If you want faster deployment, lower maintenance, and accessibility for non-developers, a no-code platform is ideal. Centerprise supports ETL and ELT, prebuilt transformations, visual pipeline design, and natural language instructions, letting teams quickly create enterprise-grade pipelines without deep coding skills. Learn more about Centerprise.
Can you combine Python code with a commercial ETL tool like Centerprise?
While Centerprise is primarily no-code, it allows for advanced transformations, prebuilt connectors, and validations. Natural language instructions and visual components cover most transformation needs, reducing the need for custom Python scripts while still providing flexibility for complex logic. Learn more about Centerprise.
Authors:
Usman Hasan Khan



